



Explaining Missing Data in Graphs: A Constraint-based Approach
Real-world graphs are incomplete: attribute values of en- tities (nodes) and relations (edges) are often missing. Enhanc- ing graphs from multiple data sources with entity matching and link prediction has been widely studied. A desirable yet missing functionality is to clarify why certain expected data is missing in graph data, whether such data can be restored, and how. Such need is evident in knowledge fusion, user-centric data quality, and query suggestion. An explanation is a sequence of operational enforcement of Σ towards the recovery of interested yet missing data (e.g., attribute values, edges). We show that constraint-based approach helps us to understand not only why a value is missing, but also how to recover the missing value. We study Σ-explanation problem, which is to compute the optimal explanations with guarantees on the informativeness and conciseness. We show the problem is in ∆P2 for established graph data constraints such as graph keys and graph association rules. We develop an efficient bidirectional algorithm to compute optimal explanations, without enforcing Σ on the entire graph. We also show our algorithm can be easily extended to support graph refinement within limited time, and to explain missing answers. Using real-world graphs, we experimentally verify the effectiveness and efficiency of our algorithms.
What is Data Constraints?
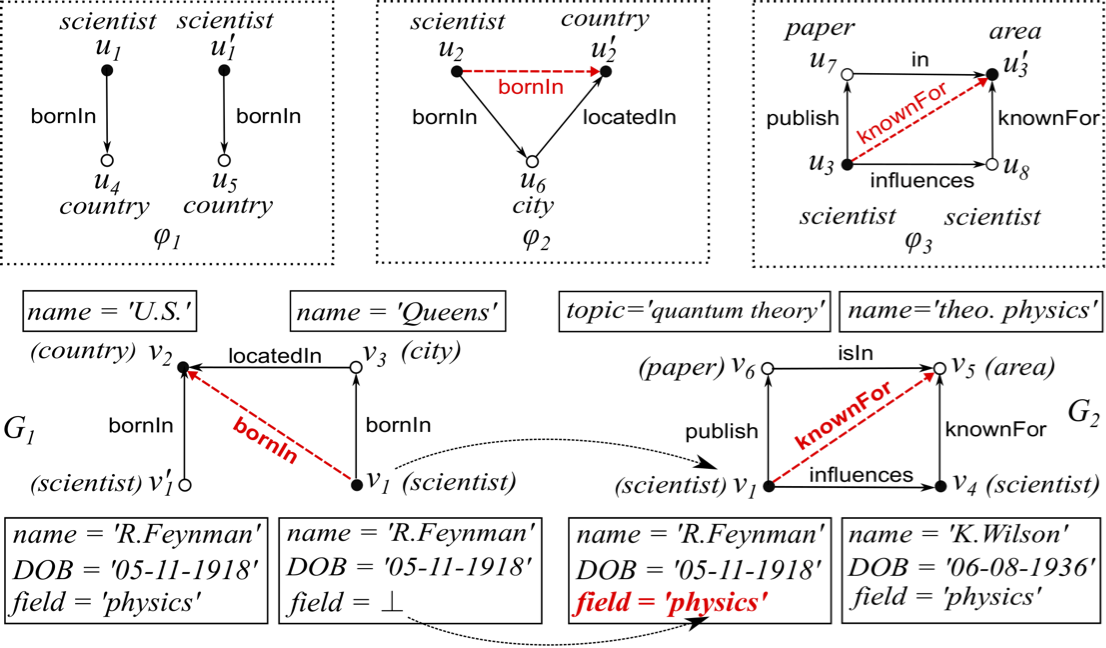
Missing data in a graph G can be captured by data constraints for graphs. These data constraints identify node pairs (v,v′) in G via graph pattern matching between a graph pattern P and a graph G, and either enforce node equivalence or assert a missing edge between v and v′. Consider the following established data constraints for graphs.
- (1) Key constraints: a general form of P → (u.id = u′.id), and state that “A pair of nodes v and v′ in a graph G should refer to the the real-world entity (id), if they both match a graph pattern P via graph pattern matching”.
- (2) Constraints that infer missing edges: P → r(u,u′) state that “There is an edge between a pair of nodes v and v′ in G with label r, if v and v′ both match P via graph pattern matching”. Notable examples include AMIE (where P are Horn clauses), conditional patterns, and graph association rules where the matching semantics of P are defined by variants of subgraph isomorphism.
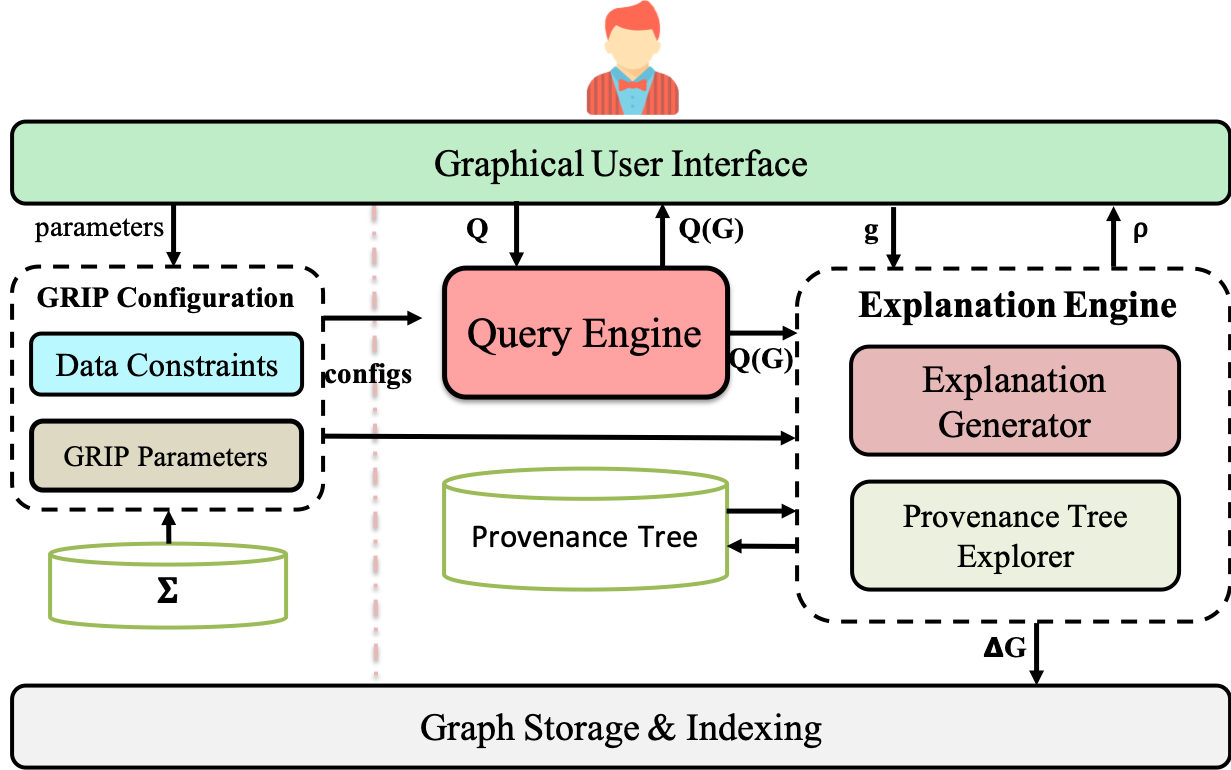
A Demo System.
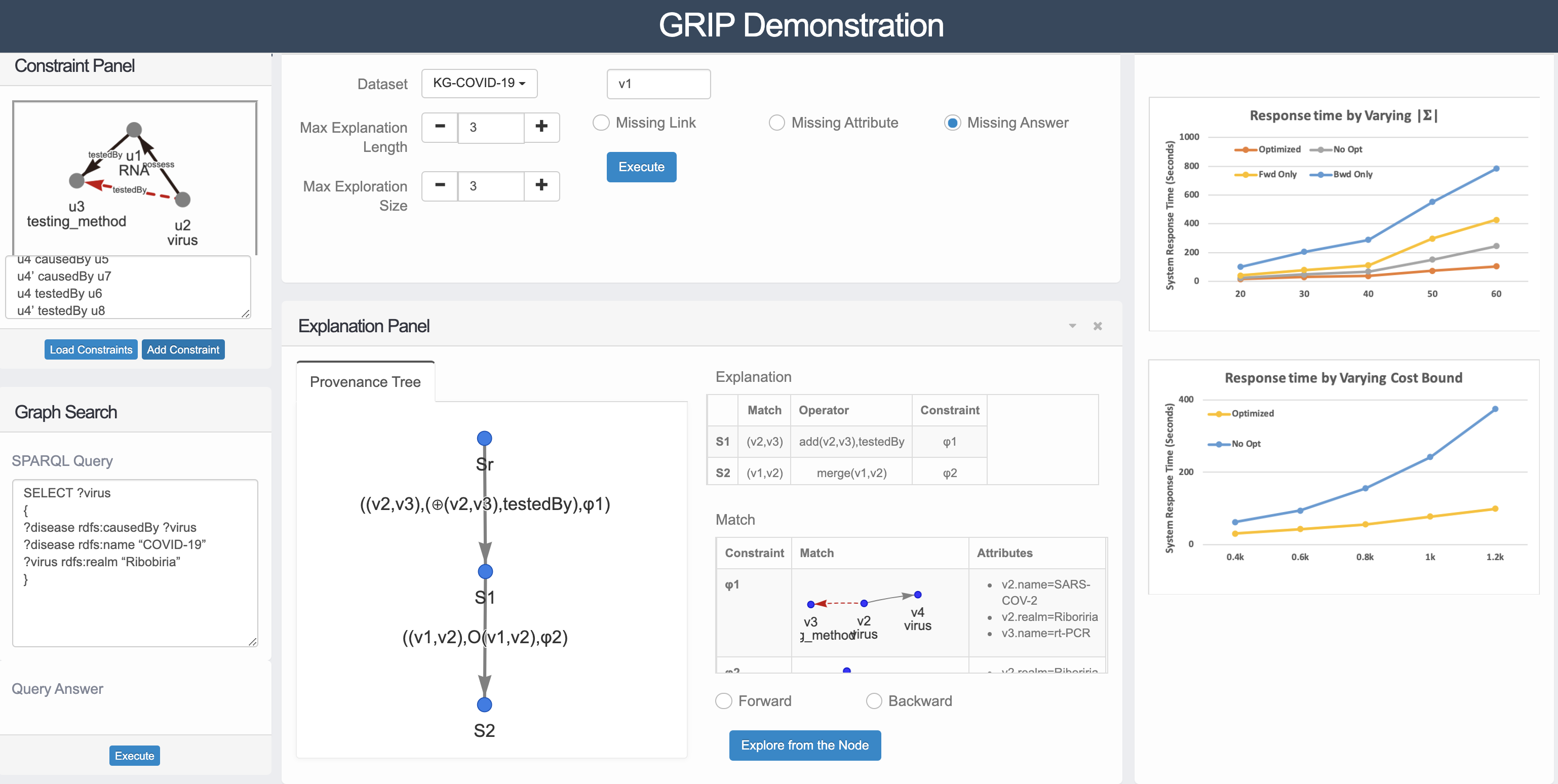
We demonstrate GRIP, a system that exploits data constraints to clarify missing answers for graph queries. (1) Constraint-based ex- planation. Given a desired yet missing entity in the query answer, GRIP ensures to generate finite and minimal sequences of data constraints (an “explanation”) that should be consecutively enforced to 𝐺 to ensure its occurrence for the same query. (2) Answering “why” and “how” questions. Users can query GRIP with both “Why” (“Why” the element is missing) and “How” questions (“How” to refine the graph to include the missing answer). GRIP engine supports run- time generation of explanations by incrementally maintaining a set of bi-directional search trees. (3) Interactive exploration. GRIP provides user-friendly GUI to support interactive ad visual explo- ration of explanations, including both automated generation and step-by-step inspection of graph manipulations.
Publications
-
Explaining Missing Data in Graphs: A Constraint-based Approach.
IEEE International Conference on Data Engineering (ICDE), 2021.
Qi Song, Peng Lin, Hanchao Ma, Yinghui Wu -
GRIP: Constraint-based Explanation of Missing Entities in Graph Search.
ACM SIGMOD Conference on Management of Data (SIGMOD (demo)), 2021.
Qi Song, Hanchao Ma, Peng Lin, Yinghui Wu
Acknowledgements
This work is supported by NSF under CNS-1932574, OIA-1937143, ECCS-1933279, CNS-2028748, DoE under DE-IA0000025, USDA under 2018-67007-28797, and PNNL Data-Model Convergence initiative.