



Knowledge Graph Summarization
Querying heterogeneous and large-scale knowledge graphs is expensive. This project studies a graph summarization framework to facilitate knowledge graph search. (1) We introduce a class of reduced summaries. Characterized by approximate graph pattern matching, these summaries are capable of summarizing entities in terms of their neighborhood similarity up to a certain hop, using small and informative graph patterns. (2) We study a diversified graph summarization problem. (a) We show that there exists a 2-approximation algorithm to discover diversified summaries. We further develop an anytime sequential algorithm which discovers summaries under resource constraints. (b) We present a new parallel algorithm with quality guarantees. (3) We also develop a summary-based query evaluation scheme, which only refers to a small number of summaries. Using real-world knowledge graphs, we experimentally verify the effectiveness and efficiency of our summarization algorithms, and query processing using summaries.
What created the need for knowledge graph summarization?
Knowledge graphs are routinely used to represent entities and their relationships in knowledge bases. Unlike relational data, real-world knowledge graphs lack the support of well-defined schema and typing system. It is hard for end-users to precise queries that will lead to meaningful answers without any prior knowledge of the underlying data graph. Querying such knowledge graphs is challenging due to the ambiguity in queries, the inherent computational complexity (e.g., subgraph isomorphism) and resource constraints (e.g., data allowed to be accessed, response time) large knowledge graphs.
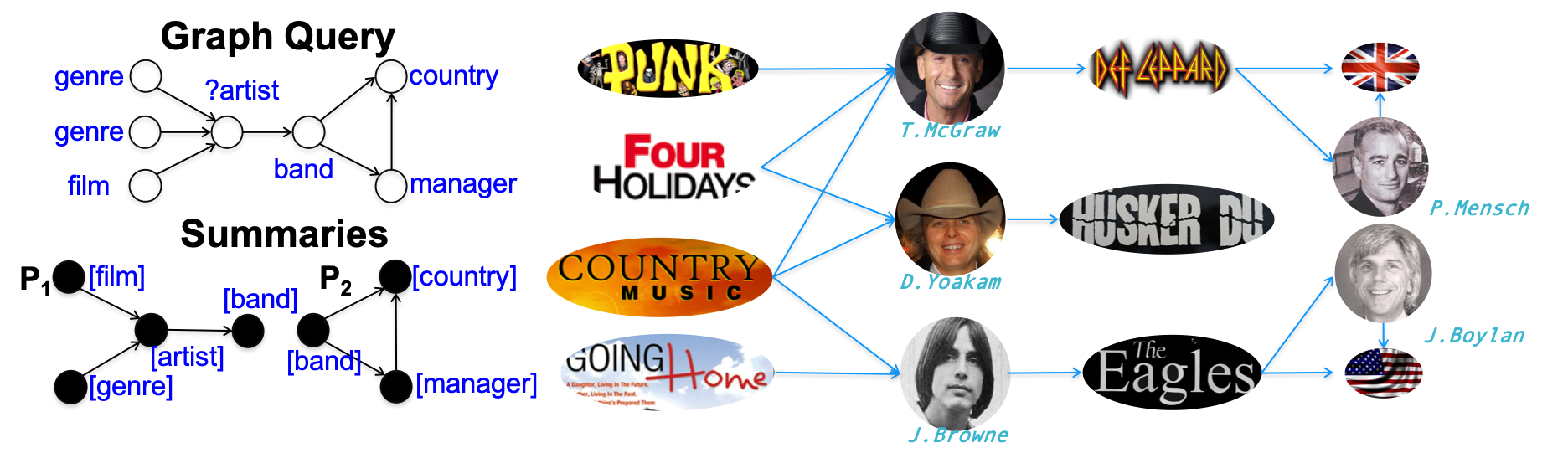
Graph patterns can benefit knowledge search by suggesting (and can be directly queried as) highly interpretable “views”. In addition, such summaries can help users in understanding complex knowledge graphs without inspecting a large amount of data, explaining facts with interpretable evidences, and suggesting meaningful queries in mining tasks.
We introduce a new class of graph patterns, namely, reduced d-summaries, to summarize entities in terms of their neighborhood simi- larity up to a bounded hop d with minimized summary size.
How to get these summaries?
We study a diversified graph summarization problem. Given a knowledge graph, it is to discover top-k summaries that maximize a bi-criteria function, characterized by both informativeness and diversity. The diversified summarization problem remains to be NP-hard for reduced summaries. We show that diversified summarization is feasible with a single processor and with multiple processors.
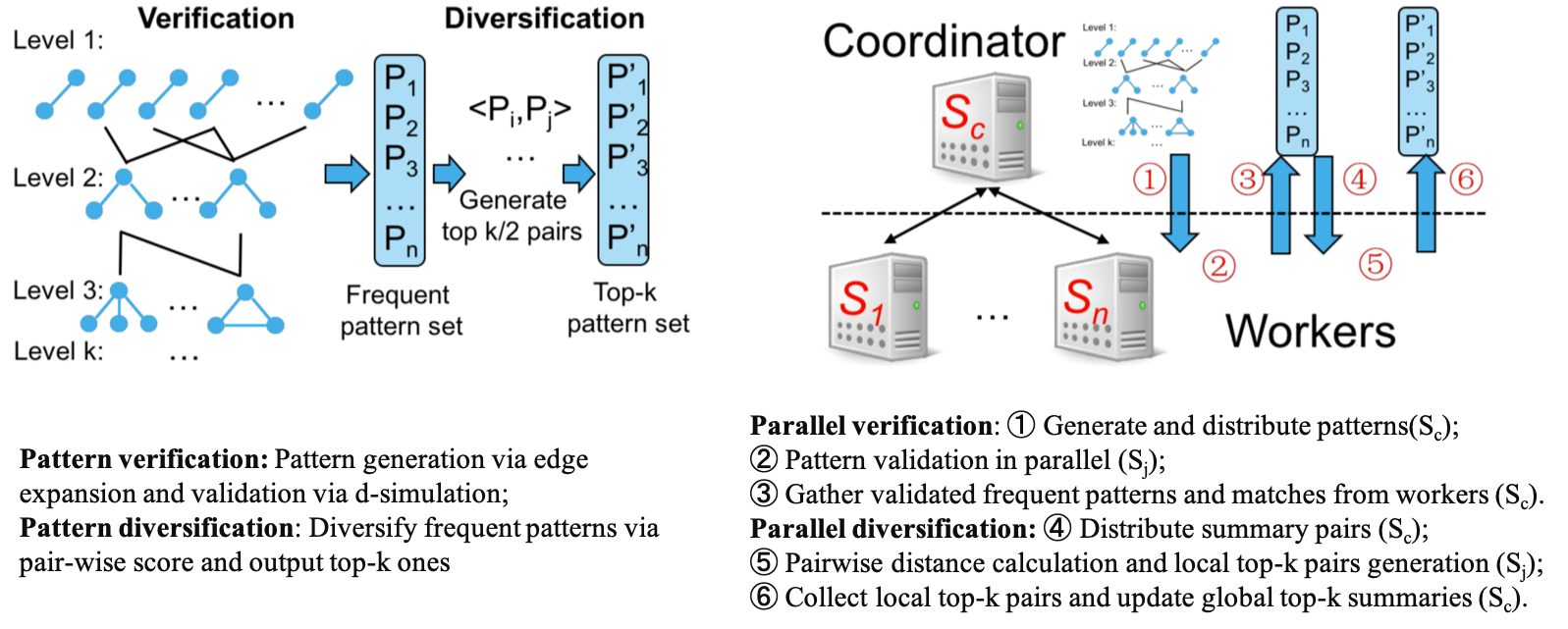
- The first algorithm is a sequential algorithm. It follows a validate-and-diversify scheme, and invokes a fast summary reduction procedure to acheive 2-approximation and anytime performance, which can be interrupted and provides “ad-hoc” summaries with desirable quality guarantees, adapting to specific resource bounds (e.g., memory, response time).
- The second parallel algorithm has the parallel scalability, a guarantee to reduce response time with the increase of processors. This ensures the feasibility of summarization in large graphs by adding processors. We have developed new parallel matching and mining operators, and load balancing strategies for reduced summary discovery.
How to use these summaries?
Reduced summaries can be used in knowledge search, query suggestion and fact checking in knowledge graphs.
- We develop a query evaluation algorithm over knowledge graphs for the class of subgraph queries. The algorithm selects and refers to a small set of summaries that best “cover” the query, and fetches entities from the original knowledge graph only when necessary.
- Reduced summaries can support ambiguous keyword search and “cross-domain” querying over multiple knowledge bases.

Datasets
We conducted experiments using real-world graphs, including DBPedia, Yago 2.0, and Freebase (version 14-04-14). We also use BSBM e-commerce benchmark to generate synthetic knowledge graphs over products with different types, related vendors, consumers, and views. The generator is controlled by the number of nodes (up to 60 M), edges (up to 152 M), and labels drawn from an alphabet of 3080 labels. All the datasets are stored in RDF in the N-triples format, a RDF importer is used to import the data into Neo4j. The details of these datasets are shown below.
| Datasets | DBPedia | Yago | Freebase | BSBM_10M | BSBM_20M | BSBM_30M | BSBM_40M | BSBM_50M | BSBM_60M |
| # of nodes | 4.86M | 1.54M | 40.32M | 10M | 20M | 30M | 40M | 50M | 60M |
| # of edges | 15M | 2.37M | 63.2M | 27M | 50M | 77M | 102M | 126M | 152M |
| # of labels | 676 | 324K | 9630 | 520 | 1100 | 1640 | 2260 | 2860 | 3080 |
Publications
-
Mining Summaries for Knowledge Graph Search. [Paper]
IEEE Transactions on Knowledge and Data Engineering(TKDE), Vol.30 (Issue No. 10), 1887-1900, 2018.
Qi Song, Yinghui Wu, Peng Lin, Luna Xin Dong, Hui Sun -
Parallel Graph Summarization for Knowledge Search. [Paper][Poster]
International Workshop on Mining and Learning with Graphs (MLG), 2017.
Qi Song, Mohammad Hossein Namaki, Peng Lin, Yinghui Wu Mining Summaries for Knowledge Graph Search. [Paper][Full Version][Slide]
IEEE International Conference on Data Mining (ICDM), 2016.
Qi Song, Yinghui Wu, Luna Xin Dong
Source Code
The source code of KGSum framework in Neo4j is available at: https://github.com/songqi1990/KnowGraphSum.
Acknowledgements
This project is supported in part by NSF IIS-1633629 and Google Faculty Research Award.