



Answering Why-Questions in Attributed Graphs
Subgraph queries have been routinely used to search graphs e.g., social networks and knowledge bases. With little knowledge of underlying data, users often need to rewrite queries multiple times to reach desirable answers. Why-questions are studied to explain missing (as “Why-not” questions) or unexpected answers (as “Why” questions). This paper makes a first step to answer why-questions for subgraph queries in attributed graphs. (1) We approach query rewriting and construct query rewrites, which modify original subgraph queries to identify desired entities that are specified by Why-questions. We introduce measures that characterize good query rewrites by incorporating both query editing cost and answer closeness. (2) While computing optimal query rewrite is intractable for Why-questions, we develop feasible algorithms, from exact algorithms to heuristics, and provide query rewrites with (near) optimality guarantees whenever possible, for both Why and Why-not questions. We also show that these algorithms readily extend to other Why-questions such as Why-empty and Why-so-many. Using real-world graphs, we experimentally verify that our algorithms are effective and feasible for large graphs. Our case study also verifies their application in e.g., knowledge exploration
What is Why-questions in Attributed Graphs?
Subgraph queries have been applied to access and understand complex networks such as knowledge bases or social networks. Given a graph G, a subgraph query Q is a (labeled) graph pattern, and the answer Q(G) of Q in G refers to subgraphs of G that are relevant to Q. The answer Q(G) can be defined by subgraph isomorphism, or approximate pattern matching.
Writing queries to search large and heterogeneous graphs is nevertheless a nontrivial task for end users. With little prior knowledge of data, users often need to revise the queries multiple times to find desirable answers. An explain functionality supported by query rewriting is thus desirable to help users understand the unexpected answers. Specifically, users may want to ask two classes of Why-questions:
- (1) Why question: “why some (unexpected) entities are in the query answer?”; and
- (2) Why-not question: “why certain entities are miss- ing from the query result?”
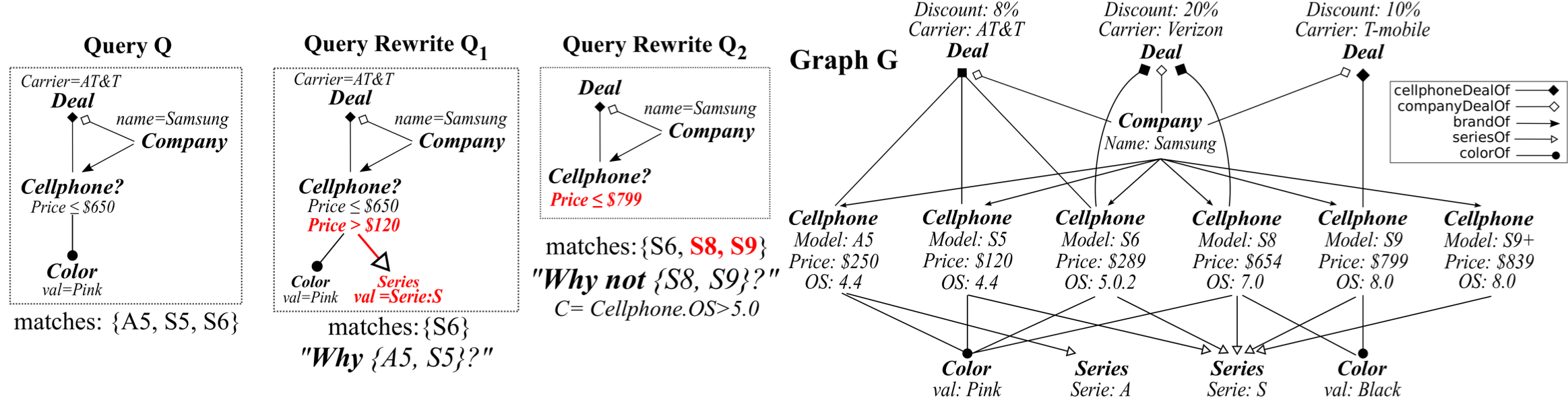
These motivate the need for developing effective query rewriting techniques to answer Why-questions for subgraph query. Specifically, given a data graph G, a subgraph query Q and answer Q(G), a set of missing entities VC with possible additional value constraints (resp. a set of unexpected entities VN in Q(G)), the problem is to modify Q to a “query rewrite” Q′, such that Q′(G) contains the entities in VC (resp. excludes the entities in VN ) as much as possible.
The need of answering Why-questions is evident in exploratory graph search. (1) The query rewrite Q′ can be readily suggested to enable iterative query processing, upon receiving users’ feedback on missing or unexpected entities. (2) The difference between the query rewrite Q′ and its original counterpart Q blends visual querying and approximate search when G is large. (3) Query rewrites also support graph exploration by suggesting entities relevant to missing and unexpected ones.
How to Generate Answers for Why-Questions?
To characterize “good” query rewrites, we introduce two measures, answer closeness and query editing cost, to measure the closeness of query rewrite answers and desired ones, and query rewrites to original queries, respectively. The cost models are defined in terms of a set of relaxation and refinement operators, aiming to tune the search conditions of Q towards desired answers. Based on the cost model, we formalize the problem of answering Why-questions, which is to compute query rewrite Q′ with optimized answer closeness given desired entities from Why-questions, under a budget B of query editing cost. We show that the problem is NP-hard for answering both Why and Why-not questions.
Despite the hardness, we develop both exact algorithms that compute optimal query rewrites, and their fast alternatives to compute high-quality query rewrites. (a) For Why questions (Section IV), we develop an exact algorithm to compute optimal query rewrite. The algorithm uses a partial enumeration scheme that requires only the verification of a class of maximal bounded operator set, instead of all possible query rewrites. In addition, we develop an approximation algorithm that achieves a near-optimality guarantee. (b) For Why-not questions, we show a counterpart of the sufficient and necessary condition for Why questions also holds, and develop an exact algorithm. We also develop a fast heuristic that computes high-quality query rewrites without any subgraph isomorphism test.
All these algorithms incur a cost that is only determined by Q and its answer, size of user-specified entities in Why-questions and editing budget, which are small in practice.
A Demo System.
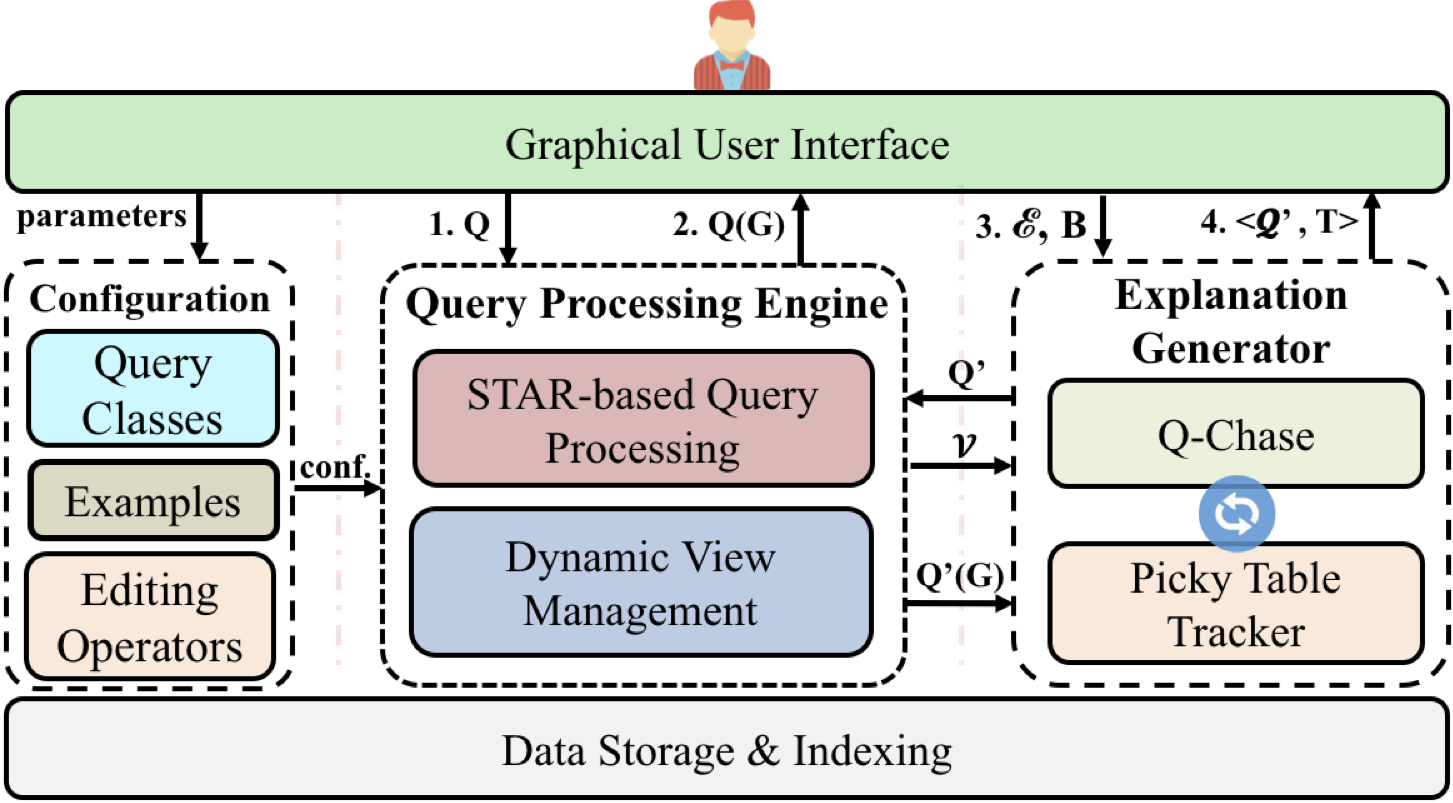
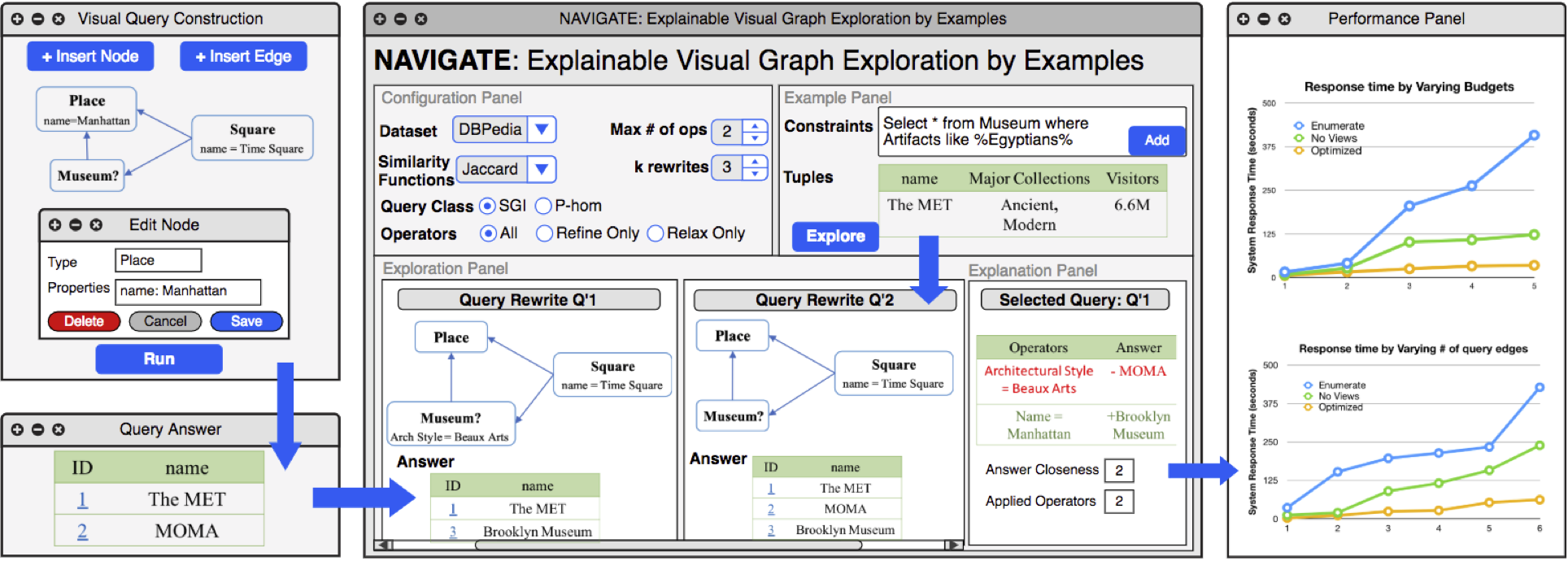
We demonstrate NAVIGATE, an explaiNAble query engine for VIsual GrAph exploraTion by Examples. NAVIGATE interleaves query rewriting and query answering to help users (1) search graphs without writing complex queries, and (2) understand answers by providing intuitive explanations. Users can visually construct queries and specify missing or unwanted example entities to guide the exploration towards desired answers.
Datasets
We conducted experiments using real-world graphs, including DBPedia, Yago 2.0, Freebase (version 14-04-14), Pokec and IMDB. We also use BSBM e-commerce benchmark to generate synthetic knowledge graphs over products with different types, related vendors, consumers, and views. The generator is controlled by the number of nodes (up to 60 M), edges (up to 152 M), and labels drawn from an alphabet of 3080 labels.
| Datasets | DBPedia | Yago | Freebase | Pokec | IMDB | BSBM_10M | BSBM_20M | BSBM_30M | BSBM_40M | BSBM_50M |
| # of nodes | 4.86M | 1.54M | 40.32M | 1.6M | 1.7M | 10M | 20M | 30M | 40M | 50M |
| # of edges | 15M | 2.37M | 63.2M | 30.6M | 5.2M | 27M | 50M | 77M | 102M | 126M |
| # of labels | 676 | 324K | 9630 | 30 | 6 | 520 | 1100 | 1640 | 2260 | 2860 |
Publications
- Answering Why-Questions for Subgraph Queries in Multi-Attributed Graphs. [Paper][Slide][Poster]
IEEE International Conference on Data Engineering (ICDE), 2019.
Qi Song, Mohammad Hossein Namaki, Yinghui Wu - Answering Why-questions by Exemplars in Attributed Graphs. [Paper][Slide][Poster]
ACM SIGMOD Conference on Management of Data (SIGMOD), 2019.
Mohammad Hossein Namaki, Qi Song, Yinghui Wu, Shengqi Yang NAVIGATE: Explainable Visual Graph Exploration by Examples.
ACM SIGMOD Conference on Management of Data (SIGMOD (demo)), 2019.
Mohammad Hossein Namaki, Qi Song, Yinghui Wu, Jiaxing Pi
Acknowledgements
This project is supported in part by NSF IIS-1633629, USDA/NIFA 2018-67007-28797 and Siemens.